基于强化学习和专家知识的呼吸机调参技术
呼吸机调参为何关键?
图1 呼吸机
在现代临床医学中,呼吸机作为一项能人工替代自主通气功能的有效手段,已普遍用于各种原因所致的呼吸衰竭、大手术期间的麻醉呼吸管理、呼吸支持治疗和急救复苏中,在现代医学领域内占有十分重要的位置。它是一种能够起到预防和治疗呼吸衰竭,减少并发症,挽救及延长病人生命的至关重要的医疗设备。
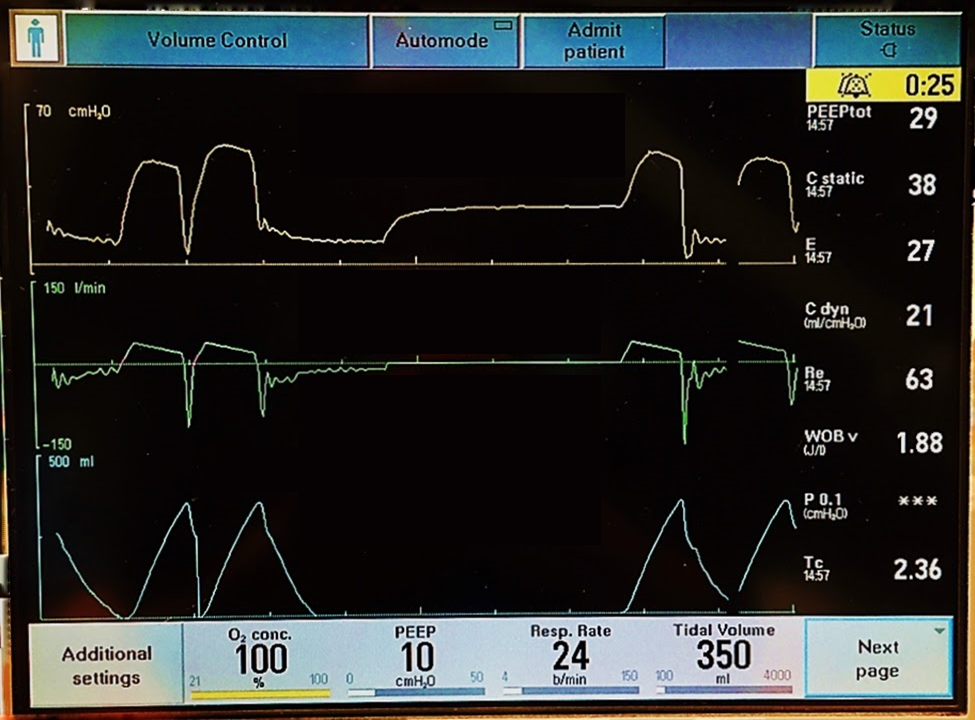
图2 呼吸机调参可视化界面
然而,呼吸机的使用并非简单的 “插上电源、设定参数” 就能了事。最佳的呼吸机设置会因患者个体的差异有所不同,通常是未知的,需要医生根据患者实际情况进行手动调整,而医生在选择这些设置时的知识和经验对自己决策的准确性有直接影响,参数调整有偏差可能会加重病情,甚至会导致死亡。比如呼吸机参数设置不当会引发肺损伤、隔膜功能障碍、肺炎和氧毒性等并发症。为了防止这些并发症并提供最佳护理,对患者进行个性化机械通气是非常有必要的。
强化学习基础与呼吸机调参的结合
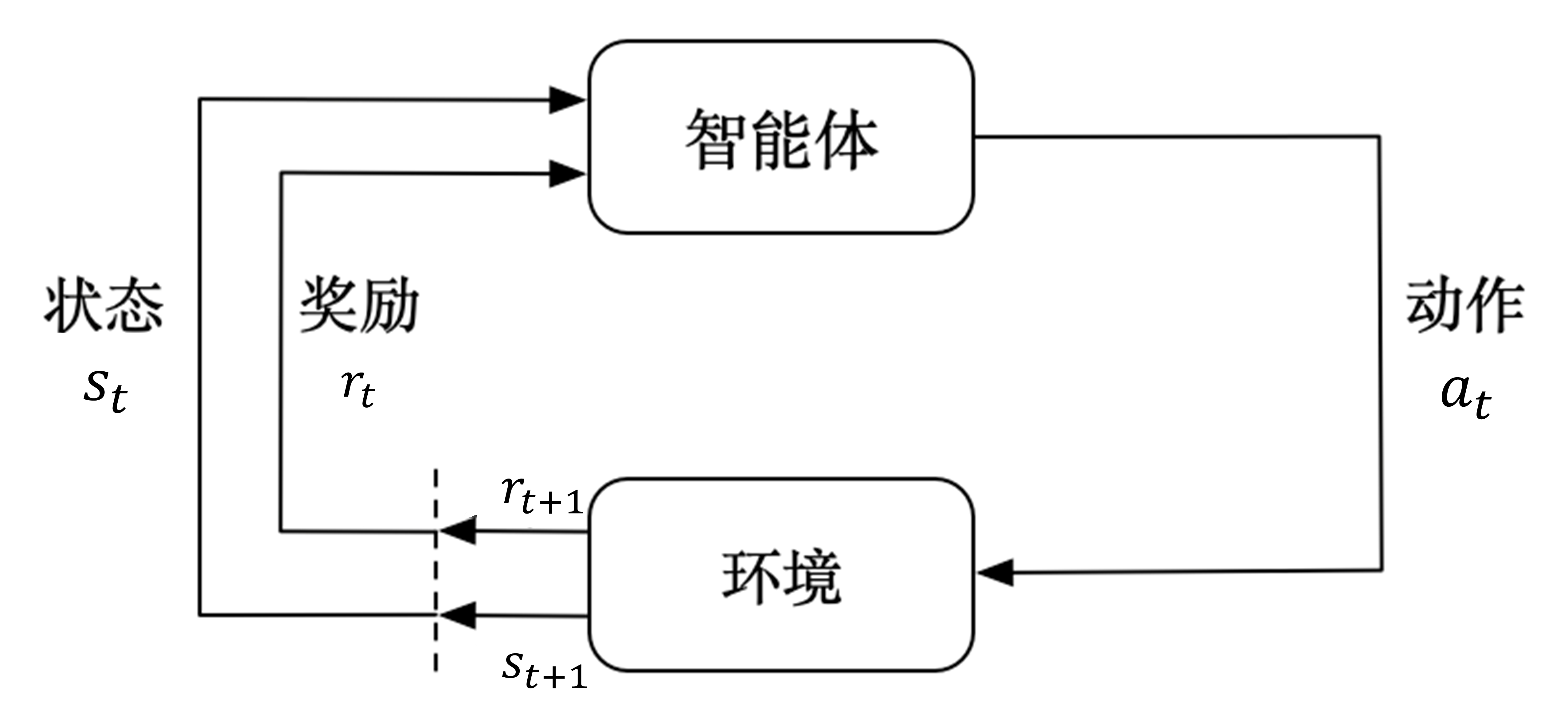
图2 强化学习流程图
那么,什么是强化学习呢?强化学习是一种机器学习的方法,其基本原理是通过智能体与环境进行交互来学习最优行为策略。智能体在环境中处于不同的状态,基于这些状态做出动作选择,环境会根据智能体的动作给予相应的奖励反馈,智能体则根据奖励来不断调整自己的策略,以实现长期累积奖励的最大化。
在呼吸机调参的情境中,我们可以将患者的生理状态(如心率、血压、血氧饱和度、呼吸频率等)视为环境状态,将呼吸机的参数调整(如潮气量、呼吸频率、吸呼比、氧浓度等)作为智能体的动作。通过强化学习算法,智能体不断尝试不同的参数组合,并根据患者生理状态的变化(即环境反馈的奖励)来学习到最佳的参数设置策略。
例如,当智能体调整呼吸机参数后,如果患者的血氧饱和度上升、呼吸平稳且没有出现其他不良反应,那么智能体就会收到一个正向的奖励;反之,如果患者出现不适或病情恶化的迹象,智能体则会收到一个负向的奖励。经过大量的这样的试错和学习过程,智能体逐渐掌握针对不同患者生理状态的最优呼吸机参数设置,从而实现个性化的精准治疗。
基于强化学习的呼吸机调参研究方法
数据获取与预处理
本研究采用 MIMIC-III 数据集,该数据集包含大量 ICU 患者临床信息,如基本信息(年龄、性别、诊断信息)、生命体征(血氧饱和度、心率、呼吸频率)、血气分析(PaO2、PaCO2 等)及呼吸机使用记录等,为研究提供了丰富的数据资源。
在数据筛选和清洗过程中,需提取与呼吸机使用时长相关的患者状态指标。针对数据中可能存在的缺失值,可采用插值法(如线性插值、多项式插值等)、均值填充或根据数据特点和分析目的选择删除缺失值等方法进行处理;对于异常值,可通过统计分析(如基于均值和标准差的异常值判断)或基于规则的算法(如设定合理的取值范围)进行识别和修正,以确保数据的准确性和可靠性。
此外,为消除量纲不一致对模型训练的影响,需对数据进行标准化或归一化处理。例如,对于数值型特征,可采用 Z-score 标准化方法,将数据转换为均值为 0、标准差为 1 的分布;或者使用 Min-Max 归一化方法,将数据映射到 [0, 1] 区间,使其适应模型训练需求。
呼吸机调参模型设计
本研究将临床治疗过程建模成马尔可夫决策过程(Markov Decision Process, MDP),其中患者的生命状态信息(如心率、血压、呼吸速率等)定义为状态(State),医生对于呼吸机参数的设置、调整等行为定义成动作(Action),患者针对医生采取动作的反馈定义为奖励(Reward),患者状态从医生采取动作前转移到采取动作后的状态称为转移(Transition)。
基于此 MDP 模型,引入强化学习算法训练代理(Agent),使其在不同状态下采取合适动作以最大化累积奖励。在强化学习算法选择方面,可根据问题特点和实际需求,选择如 Q-learning、Deep Q-Network(DQN)、Proximal Policy Optimization(PPO)、Deep Deterministic Policy Gradient(DDPG)等算法,或对这些算法进行改进和优化,以适应呼吸机调参的复杂环境。
同时,为融入临床医生的先验知识,本研究基于医生的调参经验,定义了一系列与患者病情相关的分类标准,设计一个分类模型用于根据血气分析结果对患者状态进行分类,例如将患者划分为低氧血症、高碳酸血症、酸中毒、碱中毒等不同病理状态,每一类状态对应不同的治疗优先级和参数调整建议。分类模型的引入能够为强化学习算法提供更合理的初始化策略,减少随机探索的需求,加速模型收敛,同时为决策过程提供额外约束,避免算法陷入不合理的决策路径,从而优化治疗策略,提升治疗效果。
策略评估与优化
在医疗保健环境中,由于涉及真实患者,直接采用在线强化学习的策略评估方式不安全且不符合伦理要求。因此,本研究采用 Off-Policy evaluation(OPE)的方式,基于离线策略评估来完成策略评估。具体而言,通过引入基于 Fitted Q-Evaluation(FQE)的离线策略评估方法,对策略性能进行精确估计,减少实际部署和在线验证过程中的潜在风险。
在策略优化方面,针对学习到的离线策略,可以通过对危险动作进行约束,优化策略分布偏移下的可适用性。例如,可设定合理的动作边界或基于安全规则对动作进行筛选和调整,确保呼吸机参数调整在安全有效的范围内进行,避免因不合理的参数设置对患者造成伤害,同时提高模型的稳定性和可靠性,使其能够更好地适应不同患者的临床情况,为患者提供更精准、安全的呼吸机治疗方案。
实验方案可行性分析
本研究方案具有较高的可行性,主要体现在以下几个方面:
- 数据集可用性:本研究选用的 MIMIC-III 数据集是一个广泛使用且被认可的医疗数据集,其涵盖的大量 ICU 患者临床信息,包括基本信息、生命体征、血气分析及呼吸机使用记录等,为基于强化学习的呼吸机调参研究提供了丰富且真实的数据资源,能够充分支持模型的训练、验证和评估,有助于深入挖掘呼吸机参数与患者生理状态之间的复杂关系,从而实现精准的参数调整策略的开发和优化。
- 算法适用性:深度强化学习算法在处理动态环境中的决策问题上具有独特优势,能够很好地适应呼吸机调参场景中患者生命体征不断变化的特点。通过实时反馈机制,算法可以根据患者的即时生理状态调整呼吸机参数,以优化治疗效果。例如,常用的 DRL 算法如 DQN、PPO 和 DDPG 等,能够有效处理连续状态空间和动作空间,这与呼吸机参数调节的任务需求高度契合,为实现智能化、个性化的呼吸机参数设置提供了坚实的技术基础,能够在保障患者安全的前提下,不断优化呼吸机的治疗效果,提高患者的康复率和生存质量。
- 学习资料丰富性:在深度强化学习和机器学习领域,现有的丰富学习资料能够为本研究提供全面的理论支持和实践指导。这些资料涵盖了从算法原理、模型构建到应用案例等各个方面,研究人员可以充分借鉴前人的研究经验和方法,快速掌握相关技术,并在此基础上进行创新性的研究和探索。无论是对于数据预处理、模型设计与训练,还是策略评估与优化等环节,都能够从大量的文献、教程和开源代码中获取灵感和解决方案,从而少走弯路,提高研究效率和质量,确保研究工作的顺利开展和研究目标的实现。
研究展望与挑战
随着科技的不断进步,基于强化学习的呼吸机调参研究具有广阔的前景和潜力。通过不断优化算法、积累更多高质量的临床数据以及深入融合医学专业知识,有望开发出更加智能、精准、安全的呼吸机调参系统,为临床治疗提供强有力的支持,帮助医生更好地应对复杂多变的病情,提高患者的治愈率和生活质量,推动医疗行业朝着智能化、个性化的方向发展,为人类的健康事业做出更大的贡献。
然而,我们也必须清醒地认识到,这一领域的研究仍面临着诸多挑战。例如,如何确保强化学习模型在复杂的临床环境中的稳定性和可靠性,使其能够应对各种突发状况和异常情况;如何处理数据的隐私和安全问题,在利用大量患者数据进行模型训练的同时,严格保护患者的个人信息不被泄露;如何解决模型的可解释性问题,让医生和医疗人员能够清晰地理解模型的决策过程和依据,从而更加放心地将其应用于临床实践;以及如何进一步降低模型的计算成本和资源消耗,提高其运行效率,使其能够在实际医疗场景中更加便捷地部署和使用等。这些问题都需要我们在未来的研究中不断探索和解决,以充分发挥强化学习在呼吸机调参领域的优势,为医疗事业的发展带来更多的机遇和突破。